When building a random SAR mission, many simmers would like that the locations of the target would have been in plausible locations. I think they are right, but it is not always simple to do.
In Mission-X if you want plausible locations, you would have [to]:
This is where OSM information can be helpful. If we could work with OSM files we could have a more plausible representations of locations in X-Plane, because it also use OSM data to build its networks of roads etc..
Here is a short rant I did with a fellow simmer that helped [edit] pushing me to investigate this option, although it is not ready yet and there is a long way to go before making it more streamed line.
The main challenges we face (as I see it) are:
What we came up so far:
Here are some thoughts and rants from the last test that I'm putting my script and computer to do
In Mission-X if you want plausible locations, you would have [to]:
- Prepare a list of locations ahead of time in a template, and then ask the plugin to pick one randomly.
- Leave the location to be picked randomly by the plugin, and fly there even if its location is not plausible.
This is where OSM information can be helpful. If we could work with OSM files we could have a more plausible representations of locations in X-Plane, because it also use OSM data to build its networks of roads etc..
Here is a short rant I did with a fellow simmer that helped [edit] pushing me to investigate this option, although it is not ready yet and there is a long way to go before making it more streamed line.
The main challenges we face (as I see it) are:
- How to parse the huge amount of data that is called OSM to more manageable sizes and format.
- How should we store the information.
- What is the workflow to extract the information and prepare the end file.
- Can we provide the simmers a tool/script to do that so they can freely prepare their own osm files.
What we came up so far:
- Parsing should be done in few stages and tools.
- Use osmconvert and osmfilter to prepare a smaller and more optimized file that represent only the information we need/want in OSM format (which is XML).
- We will use the SQLite database to store relevant data to the plugin.
- I used PERL scripting to analyze the files and prepare the SQLite databases.
PERL is a cross-platform scripting language that let me focus on the flow itself and not on the code.
I tested it on Linux and Windows and it works quite well.
Here are some thoughts and rants from the last test that I'm putting my script and computer to do
==== Start of mail =====
Hi {name...},
Another update.
Yesterday I tried the script on US region, the whole region of US.
Its base size is 80G as OSM file and the number of rows is 2+ Billion.
At first I was naive and thought, lets give it a shot, but very quickly I found out that the performance was really bad, it took almost an hour for 500K of elements to process into the SQlite database.
That is not a good performance by any standard.
As someone who works with databases, I quickly searched how to make the performance better, and to my joy I found this nice article that explains how to make transactions in SQLite, something that I take for granted from commercial databases, but not so in SQLite.
I then did minor tweaking to the script, The transaction prepared 50K of rows and only then commit to the database. This is in contrast to the "commit every row" policy that is the default.
Bottleneck has been removed and the script now write much faster to the database.
Here are some stats:
Average of writing 500K of rows into the database: <~15sec (down from ~3000+ sec before).
Size of the <node> database: 23G
Size of the <way> database is ~5G but still growing as of this writing.
Time to process all US <node> elements and write to SQLite: ~25000 sec
I'm still waiting for the <way> nodes to finish.
Here are some screenshots:
Before optimizing insert statements:
Hi {name...},
Another update.
Yesterday I tried the script on US region, the whole region of US.
Its base size is 80G as OSM file and the number of rows is 2+ Billion.
At first I was naive and thought, lets give it a shot, but very quickly I found out that the performance was really bad, it took almost an hour for 500K of elements to process into the SQlite database.
That is not a good performance by any standard.
As someone who works with databases, I quickly searched how to make the performance better, and to my joy I found this nice article that explains how to make transactions in SQLite, something that I take for granted from commercial databases, but not so in SQLite.
I then did minor tweaking to the script, The transaction prepared 50K of rows and only then commit to the database. This is in contrast to the "commit every row" policy that is the default.
Bottleneck has been removed and the script now write much faster to the database.
Here are some stats:
Average of writing 500K of rows into the database: <~15sec (down from ~3000+ sec before).
Size of the <node> database: 23G
Size of the <way> database is ~5G but still growing as of this writing.
Time to process all US <node> elements and write to SQLite: ~25000 sec
I'm still waiting for the <way> nodes to finish.
Here are some screenshots:
Before optimizing insert statements:
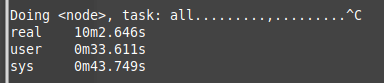
You can see I have stopped the process after 10min since it only processed ~100K of node elements.
After first time optimization (adding transactions):
You can see it processed in 10min more than none-optimized code.
After first time optimization (adding transactions):
You can see it processed in 10min more than none-optimized code.

Well, I bet there are other optimization that I might add, but not sure it is worth the time since it is quite fast now and for small % bump I don't want to waste to much time.
Optimization I did so far:
Quick optimization I thought are:
With the current state of the script, it should take few minutes to analyze small to medium osm areas. For countries and continents we will need much more time and disk space to make it work.
We still need to check how much time will it take for a plugin to read from the database, and do we need to restrict it to a manageable area to speed the query (make sense).
That was a long rant, I think I'll share it on my site too.
Cheers
Saar
==== End of mail =====
Optimization I did so far:
- Removed OSM xml tags that we do not need:
./osmconvert64-0.8.8p.exe {file}.pbf --drop-relations --complete-multipolygons --drop-author --drop-version -o={output file}.o5m
The "o5m" is much smaller than "osm" which will be our format to go with the perl script.
./osmfilter {file}.o5m --drop-node-way-tags="created_by= source*= oneway= lanes= horse= surface= maxspeed= ref= hgv*= sidewalk= name:*= old_name*= isolation= prominence= wiki* alt*= attrib*= geobase*= tiger*=" --drop-ways="natural=coastline" > {file}-filtered.osm
We can continue and optimize this "osm" file and remove more "tags" that we do not need as we have more OSM files to work on (and learn from). - Removed <node> sub elements extraction and only focus on <way> sub elements information (they will probably include the <node> data too, so why have them both).
- All <node> information will be loaded to its own table first (with PK on the node ID column).
- <way> nodes will be processed only after <node> elements are done.
- Look up for the sub element "<nd ref="node id" />" is done against the "<node>" table instead of doing a recursive file search.
This reduced the search from minutes to less than a second for one "ref" search. - We construct 2 databases.
One database for only <node> elements (look up table).
One database for the <way> information.
The real database that we will need to use in Mission-X plugin will be the <way> database. It is even smaller than the <node> database and holds only the data we need,
Quick optimization I thought are:
- The table "way_data" is not really needed, since the information is already written inside table: "way_tag_data".
This can save some space in the <way> database and shave more seconds from the overall load process. - Create tables without Primary Key columns.
- Add indexes at the end of the loading process.
- Parallel, This is more a wishful thinking since I don't think that the amount of work I'll invest in this will worth it, especially if SQLite is not optimized for multiple writes from different processes. I think it is more tuned to 1 on 1 interaction (never checked that).
- If Sqlite support functions, then maybe the function will do all the SQLite processing for the external plugin and will return a string with all the information we need to construct one location.
The balancing of "pure" osm file reading vs "template file + osm reading" will be investigated later.
With the current state of the script, it should take few minutes to analyze small to medium osm areas. For countries and continents we will need much more time and disk space to make it work.
We still need to check how much time will it take for a plugin to read from the database, and do we need to restrict it to a manageable area to speed the query (make sense).
That was a long rant, I think I'll share it on my site too.
Cheers
Saar
==== End of mail =====
[Edited]
Here are the results of the US run:
Here are the results of the US run:
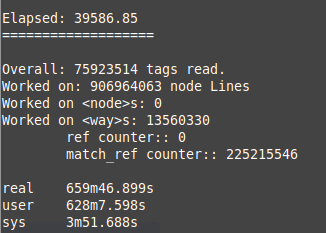 |  |
You can see that there were more than 200M queries to match "ways reference points" to "node" locations.
You can also see that the "way"s database size is roughly ~50% smaller than the "node" database one, which make it more manageable in terms of sharing.
Further more, if we compress the "ways" database file, the file size is reduced to 2.5G.
We can see how the optimizations of the OSM file reduces the file from 83G of uncompressed OSM (xml format) file size, to a ~10G of database size ot 2.5G compressed size.
If this will prove worthwhile, then we can prepare such information for major regions and hopefully it will satisfy simmers.
Please do remember that this option is optional and thus can save space on disk if you do not want it or prefer much smaller OSM regions.
You can also see that the "way"s database size is roughly ~50% smaller than the "node" database one, which make it more manageable in terms of sharing.
Further more, if we compress the "ways" database file, the file size is reduced to 2.5G.
We can see how the optimizations of the OSM file reduces the file from 83G of uncompressed OSM (xml format) file size, to a ~10G of database size ot 2.5G compressed size.
If this will prove worthwhile, then we can prepare such information for major regions and hopefully it will satisfy simmers.
Please do remember that this option is optional and thus can save space on disk if you do not want it or prefer much smaller OSM regions.
There are still information that needs to be extracted from the table and decide how to approach it when working with an external application like Mission-X, my thought is to try and keep what standards we currently have, and build upon them.
I did not finalized how it should be done, yet, but it is fun to pick locations from the databae and check them in Google Earth and see how they match.
There is also a balance that I think needs to be taken into consideration between random location from the OSM database and the rest of the mission.
For example: Lets assume we construct a SAR mission that has an accident location and then we need to take the injured person to hospital.
The OSM database can easily pick a plausible location in the lat/long area we are stationed in. It will probably have a representation (especially roads) in X-Plane since they also use OSM data.
But, then we need to take the injured person to a hospital or other location that is in X-Plane and not the OSM file.
Here is where the balance should take place. I think that target location can be taken from OSM, but the rest of the locations we should "ask" X-Plane or our predefined "template" information to pick for us.
This balancing is important to construct a better and more plausible mission cases.
Even though I do not have an expected implementation time table, it was fun to work on the Perl script and optimize it so it will produce useful results.
I hope to share this work with you all soon.
Until next time
Blue Skies
Saar
I did not finalized how it should be done, yet, but it is fun to pick locations from the databae and check them in Google Earth and see how they match.
There is also a balance that I think needs to be taken into consideration between random location from the OSM database and the rest of the mission.
For example: Lets assume we construct a SAR mission that has an accident location and then we need to take the injured person to hospital.
The OSM database can easily pick a plausible location in the lat/long area we are stationed in. It will probably have a representation (especially roads) in X-Plane since they also use OSM data.
But, then we need to take the injured person to a hospital or other location that is in X-Plane and not the OSM file.
Here is where the balance should take place. I think that target location can be taken from OSM, but the rest of the locations we should "ask" X-Plane or our predefined "template" information to pick for us.
This balancing is important to construct a better and more plausible mission cases.
Even though I do not have an expected implementation time table, it was fun to work on the Perl script and optimize it so it will produce useful results.
I hope to share this work with you all soon.
Until next time
Blue Skies
Saar
 RSS Feed
RSS Feed
